



Pipeline Network Performance Using Machine Learning

An extensive water pipeline network consisting of several interconnected pipelines supplies water to various pump stations. The system has been in place for many years and has experienced serious issues with corrosion/erosion and below-expected flow rate delivery at various points in the system. To help understand the potential causes, flow meters at various points were installed to gather data. Penspen’s scope was to develop a model of the network to enable the efficient assessment of the network performance. The work was executed by the Centre of Engineering Excellence (CEE).
Initial Assessments
Initial data assessment of the flow meters suggested lower than expected flow, with at least one pipeline almost entirely blocked. The usual method is to develop a flow assurance model and perform simulations to assess the network performance. The challenge in undertaking performance analysis of this system is obtaining a complete set of input data in the form of boundary conditions for the 3 inputs and 9 outputs and dealing with the continuously changing conditions with start-ups and shutdowns of individual pump stations.
Machine Learning Overview
As an alternative, the flow rate data already gathered was used to develop a machine learning model of the system. Use of machine learning algorithms to build a model of the system that predicts outputs based on inputs. Machine learning algorithms are used to build a model based on sample data, known as “training data”, to make predictions or decisions without being explicitly programmed to do so. The model was used on two datasets: before and after installation of additional equipment, with the former used as the training data and the latter as the test data. Air valves were installed and flow rate data before and after their installation was available. This approach allows for a significantly faster method to assess changes to the system to determine potential causes & also assess the impact of mitigation measures. Another benefit is that it does not need a full data set, though more data will increase the accuracy. This can be particularly advantageous where only incomplete input data is available, which can be the case with aging assets.
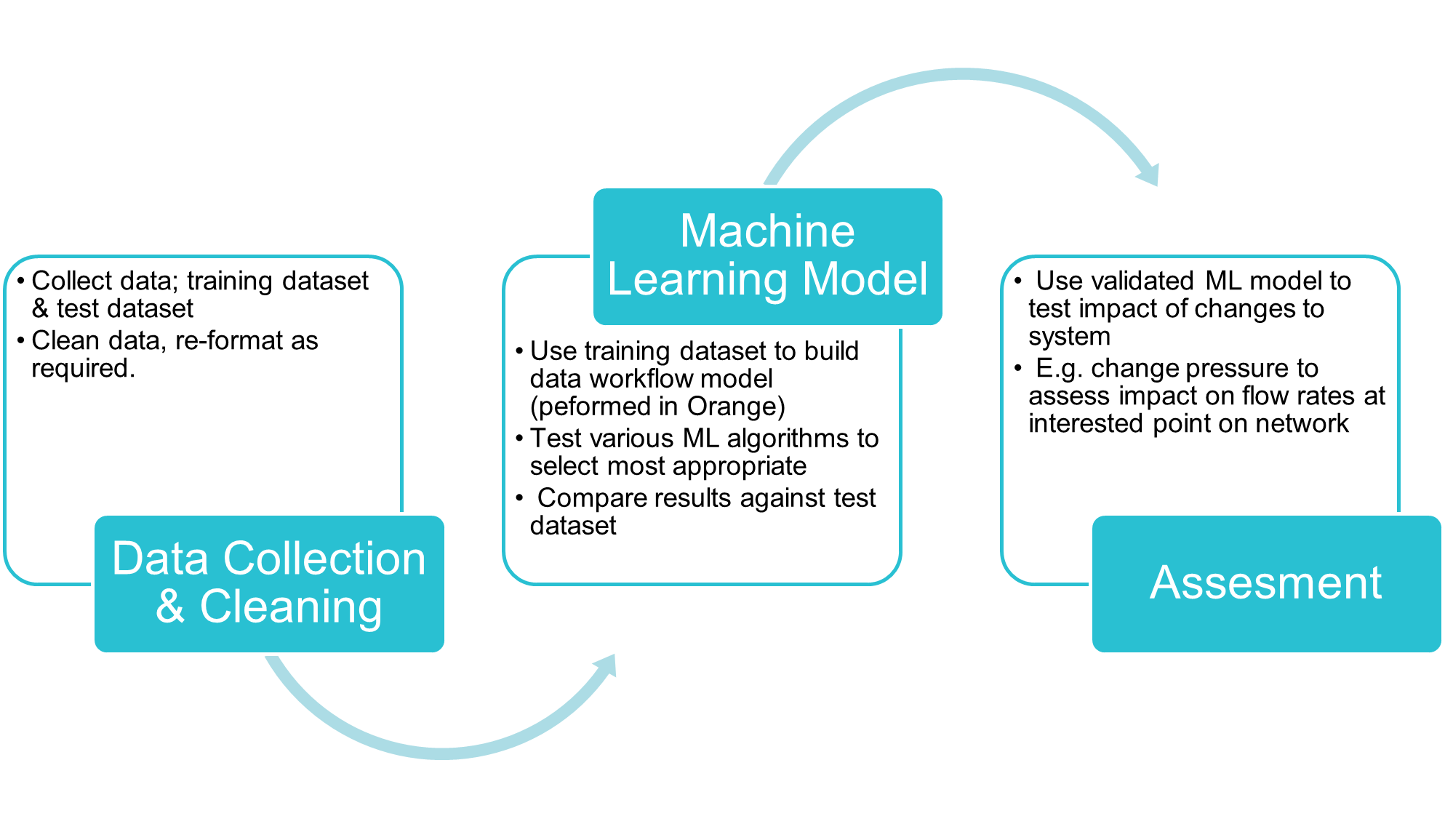
Machine Learning Model
For this study Machine learning was performed using Orange software. Orange is a component-based visual programming software package for data visualization, machine learning, data mining, and data analysis. Visual programming is implemented through an interface in which workflows are created by linking predefined or user-designed widgets. A bespoke workflow was developed for this project – see figure below.
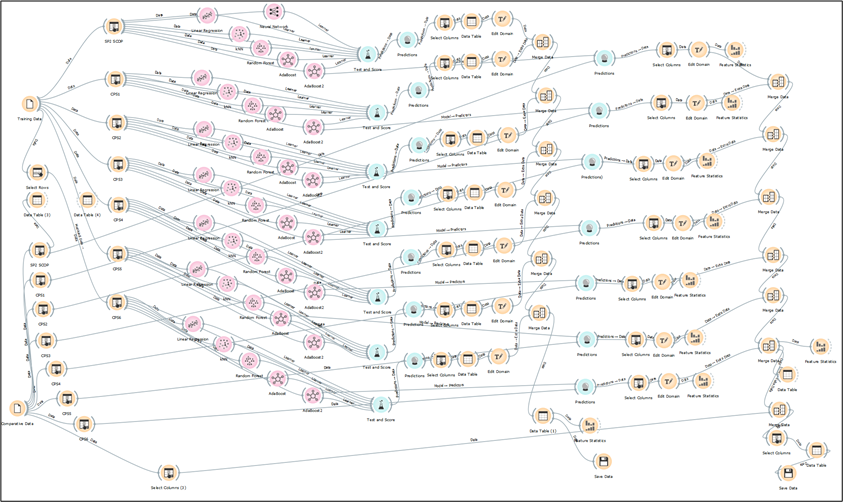
Model Testing
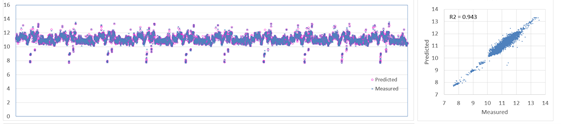
Model testing yielded good results. Individual plots of measured and predicted, and unity plots were created at each pump station location, an example is shown below.
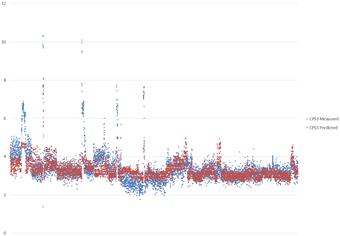
Run with Test Data
The validated machine learning model was subsequently run with input data from the test dataset. The comparison of predicated and measure data points at a particular location are shown below.
Conclusion
The machine learning methodology proved to be an accurate and efficient method for comparing performance. It has the advantage of not needing a complete dataset and relatively straightforward to set up. This allows for fast evaluation of results to changes in inputs to identify trends to assess network performance. As more data is gathered over life, this can be added to augment the model and improve accuracy. The model maintenance requires minimal effort, yet provides a close.
This work was performed by Penspen’s Centre of Engineering Excellence (CEE), which provides advanced analytics and simulation services as one of their main offerings. To find out more information on the performance of pipelines and our capabilities at the CEE, email our Executive Vice President, Technical Excellence, Nigel Curson.
Insights & News

Managing Electrical Interferences in Pipelines – A Practical and Cost-Effective Approach
The rapid expansion of AC/DC transmission networks, electrified transportation systems and pipeline infrastructure has increased the spatial overlap among these...

Growth Across Borders: Meet Nilesh
A lifelong passion for continuous improvement has seen Nilesh soar in his career. Now, as Principal Mechanical Engineer at Penspen, he's using his experience to mentor graduate...

Engineering Intelligence: The Women Building Digital Careers in Energy
On International Women’s Day, we talk to two software engineers about how data is transforming how engineers work, the personal qualities required for a role in software development, and why their...

Exceedance Probability Modeling in Pipeline Integrity Using Big Data Techniques for Crack Type Anomalies
In our latest technical insight, Penspen Asset Integrity experts explore how exceedance probability modelling and big data techniques can be applied to crack-type anomalies to support risk-based...

Penspen Latin America Director Appointed to AMPP Global Technical Advisory Committee
International engineering consultancy Penspen is pleased to announce that Gustavo Romero, Director – Operations (LATAM), has been appointed to the Global Technical Advisory Committee (GTAC) of the...

Penspen Launches Three New Asset Integrity Training Courses in the Middle East & Africa Region
Penspen has launched three new Asset Integrity online training courses across the Middle East & Africa (MEA) region, supporting operators in strengthening pipeline integrity and managing ageing...

Penspen Awarded Hydrogen Transition Pathways for Industrial Clusters Study
International energy consultancy Penspen has been awarded a critical research project designed to look into how hydrogen can support the transition of the UK’s industrial clusters. Hydrogen...
More insights
-

Managing Electrical Interferences in Pipelines – A Practical and Cost-Effective Approach
The rapid expansion of AC/DC transmission networks, electrified transportation systems and pipeline infrastructure has increased the spatial overlap among these assets.…
Read insight -

Growth Across Borders: Meet Nilesh
A lifelong passion for continuous improvement has seen Nilesh soar in his career. Now, as Principal Mechanical Engineer at Penspen, he's using his experience to mentor graduate engineers.…
Read insight